What is KV-Caching?
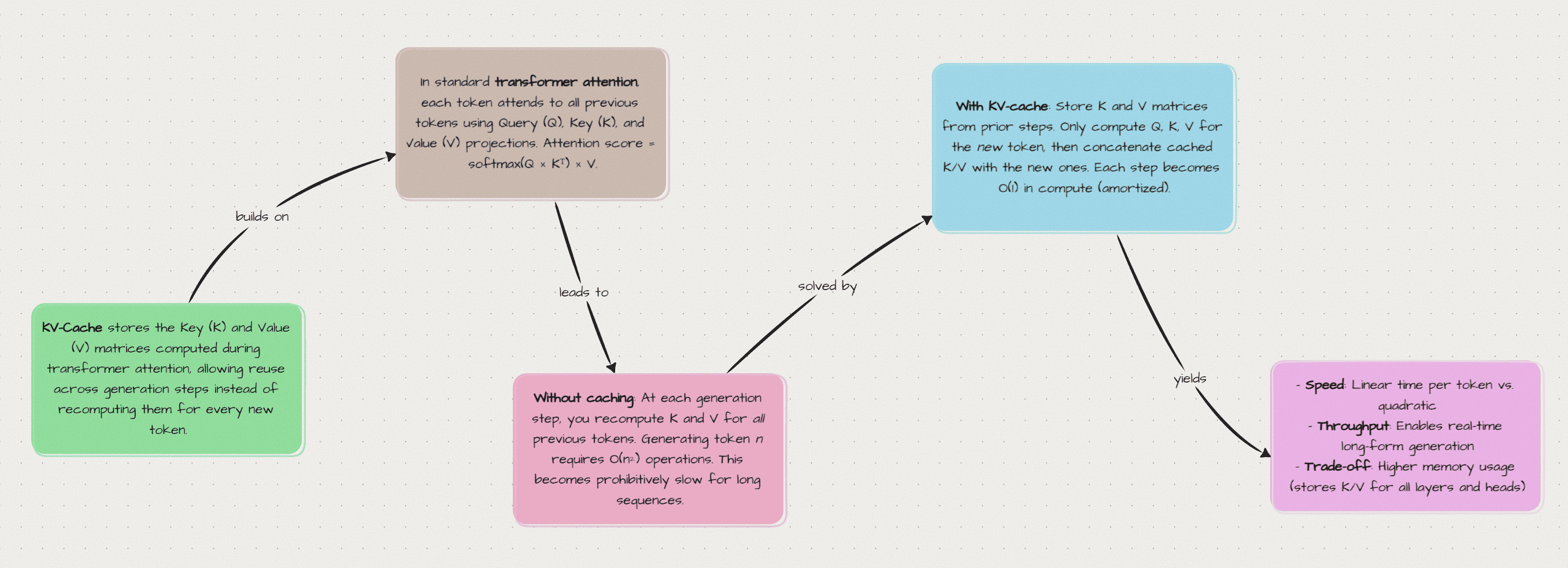
KV-caching is an optimization technique used when running transformer models (like GPT, Claude, or Llama) to generate text. It saves time by “remembering” computations from previous steps instead of recalculating them.
At its core, KV-caching stores two matrices — Keys (K) and Values (V) — so that when generating text token by token, the model only computes projections for the new token, not the entire sequence.
Part 1: How Attention Works (The Foundation)
Before understanding KV-caching, you need to understand attention, the core mechanism inside transformers.
The Search Analogy
Imagine you’re in a library looking for information:
- Query (Q): Your question — “What books discuss neural networks?”
- Keys (K): The catalog/index cards describing each book’s contents
- Values (V): The actual books themselves with all their information
Attention works by:
- Comparing your Query to every Key (how relevant is each book to your question?)
- Getting a relevance score for each book
- Taking a weighted combination of the Values (reading the most relevant books)
The Math (Simplified)
For each token in your input, the transformer creates three vectors:
Query = W_q × hidden_state (What am I looking for?)
Key = W_k × hidden_state (What do I contain?)
Value = W_v × hidden_state (What information do I have?)The attention score is calculated as:
Attention(Q, K, V) = softmax(Q × K^T / √d) × VThis means every token “attends to” (looks at) every other token in the sequence.
Part 2: The Problem — Why Naive Generation is Slow
When a language model generates text, it works autoregressively — one token at a time:
- Input: “The cat sat”
- Output: “on”
- New input: “The cat sat on”
- Output: “the”
- New input: “The cat sat on the”
- Output: “mat”
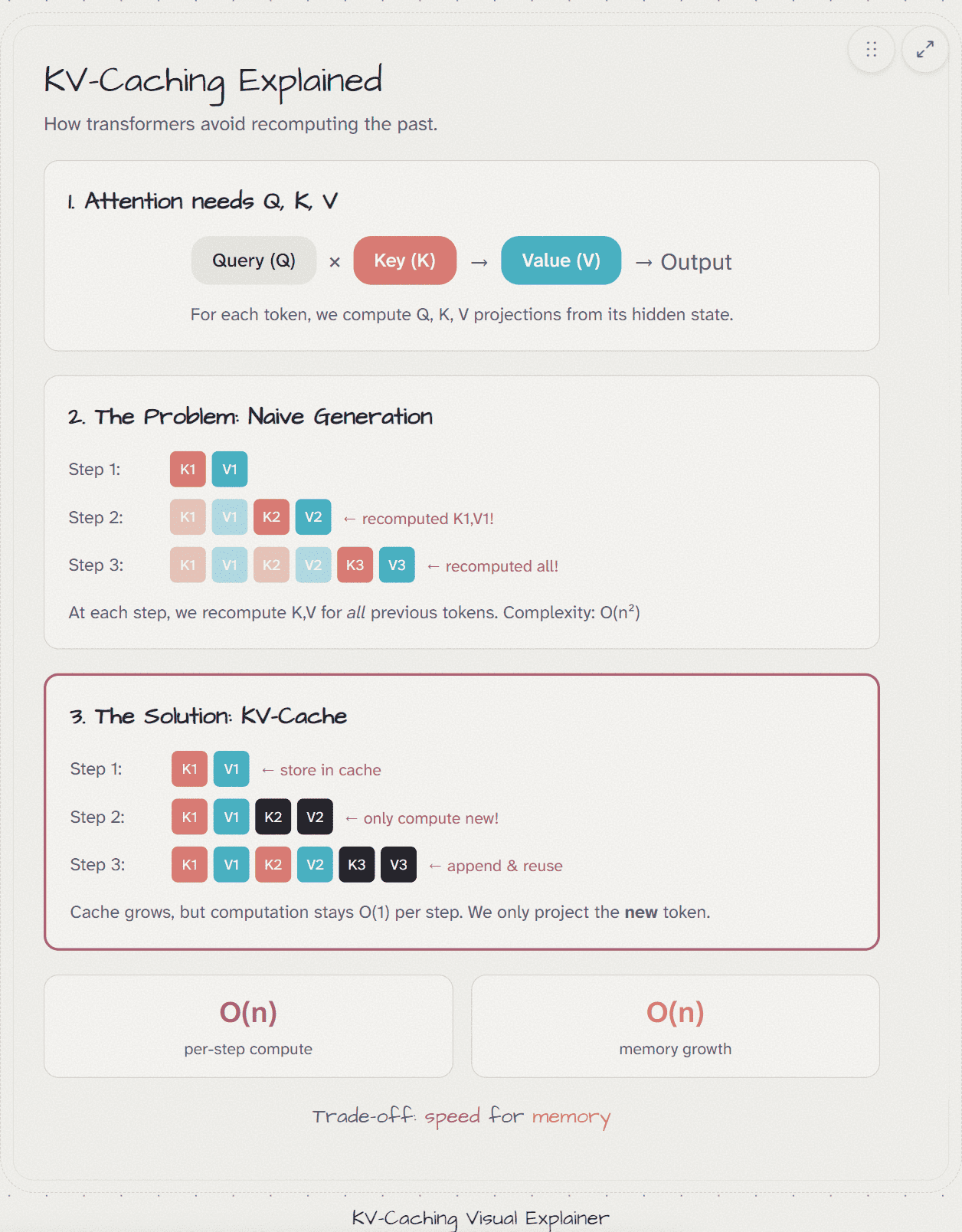
The Naive Approach (Without Caching)
At step 5, when processing “The cat sat on the”, the naive approach would:
- Project every token (“The”, “cat”, “sat”, “on”, “the”) to get Q, K, V matrices
- Compute attention over all 5 tokens
- Generate the next token
At step 6, when processing “The cat sat on the mat”:
- Project all 6 tokens again (even though 5 haven’t changed!)
- Compute attention over all 6 tokens
- Generate the next token
The waste: Tokens 1-5 haven’t changed, but we recompute their K and V projections every single step!
Complexity Analysis
- Step 1: Process 1 token
- Step 2: Process 2 tokens
- Step 3: Process 3 tokens
- …
- Step n: Process n tokens
Total work: 1 + 2 + 3 + … + n = O(n²)
For generating 1000 tokens, you’re doing ~500,000 token projections instead of 1,000!
Part 3: The Solution — KV-Caching
The Key Insight
Once a token is processed, its Key and Value projections never change. Only the Query for the new token needs to be computed.
Why Only K and V? (The Active vs. Passive Distinction)
You might wonder: Q, K, and V are all computed from a token’s hidden state — why cache only K and V?
The answer lies in how attention uses each matrix:
| Matrix | Role | Why It’s Cached (or not) |
|---|---|---|
| Query (Q) | Active — asks “what should I look for?” | Only needed when token i is being generated. Once token i exists, it never needs to “ask questions” again. |
| Key (K) | Passive — answers “what do I contain?” | Every future token needs to look up token i’s info. K_i must stay in cache so future queries can find it. |
| Value (V) | Passive — provides “here’s my information” | Same as K — future tokens need to retrieve token i’s actual content. |
The asymmetry: When generating token N+1, we compute a fresh to “ask questions” about all previous tokens. But we only need to look up cached … and … — we never need old Q’s again.
The math makes this concrete:
When generating token N+1, the attention computation is:
Notice:
- appears once (the new token’s query)
- … are retrieved from cache (previously computed)
- … are retrieved from cache (previously computed)
- The old queries … do not appear — they’re irrelevant for generating token N+1
Why? Because attention computes how the current token relates to all previous tokens. Once token i was generated, we used to determine what it should attend to. That decision was made and finalized — we don’t revisit it.
Think of it like a library:
- Q = A patron’s question (only relevant while they’re asking)
- K = Catalog cards (permanent reference for all future patrons)
- V = The books themselves (permanent content for all future patrons)
You keep the catalog and books (K, V) but discard the old questions (Q).
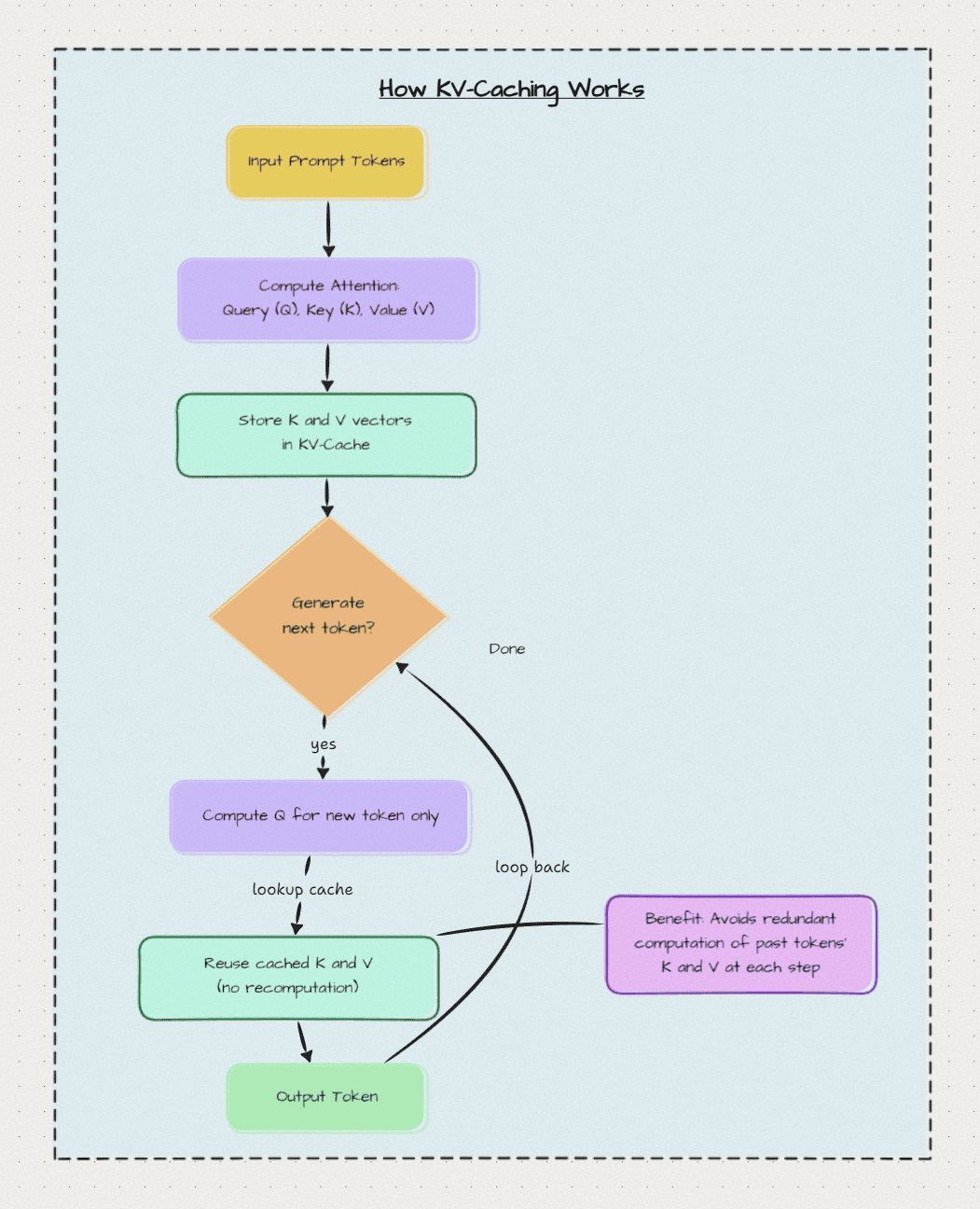
How KV-Caching Works
Step 1: Process the initial prompt
- Compute Q, K, V for all prompt tokens
- Store K and V in the cache
Step 2: Generate first new token
- Compute Q, K, V for just the new token
- Append new K, V to cache
- Use cached K, V + new K, V for attention
- Generate next token
Step 3: Generate second new token
- Compute Q, K, V for just the new token
- Append new K, V to cache
- Use all cached K, V for attention
- Generate next token
Visual Example
Without caching (Step 3 of generation):
Recompute: [K₁,V₁] [K₂,V₂] [K₃,V₃] [K₄,V₄] [K₅,V₅] + [K₆,V₆]
↑ redundant! ↑ redundant!With caching (Step 3 of generation):
Cache: [K₁,V₁] [K₂,V₂] [K₃,V₃] [K₄,V₄] [K₅,V₅]
Compute: [K₆,V₆]
↑ only this!Complexity Analysis (With Caching)
- Step 1: Process 1 new token
- Step 2: Process 1 new token
- Step 3: Process 1 new token
- …
- Step n: Process 1 new token
Total work: 1 + 1 + 1 + … + 1 = O(n)
Speedup: From O(n²) to O(n) — for 1000 tokens, that’s ~500× faster!
Part 4: The Trade-Off
KV-caching isn’t free. It trades memory for speed:
| Aspect | Without Cache | With Cache |
|---|---|---|
| Compute per step | O(n) | O(1) |
| Memory usage | O(1) | O(n) |
| Total generation time | O(n²) | O(n) |
The cache grows with sequence length. For a model with:
- Hidden dimension: 4,096
- 32 attention heads
- 8,192 context length
The KV-cache requires storing:
- 2 matrices (K and V)
- × batch size
- × number of layers
- × sequence length
- × hidden dimension
This can be gigabytes of GPU memory for long sequences!
Part 5: Real-World Context — Provider Caching
The KV-caching concept extends to API-level “prompt caching” offered by OpenAI, Anthropic, and others:
How It Works
- First request: Your prompt is processed, KV-cache computed and stored server-side
- Second request (same prefix): The provider reuses the cached KV matrices
- Result: Faster responses and lower costs (50-90% discount on cached tokens)
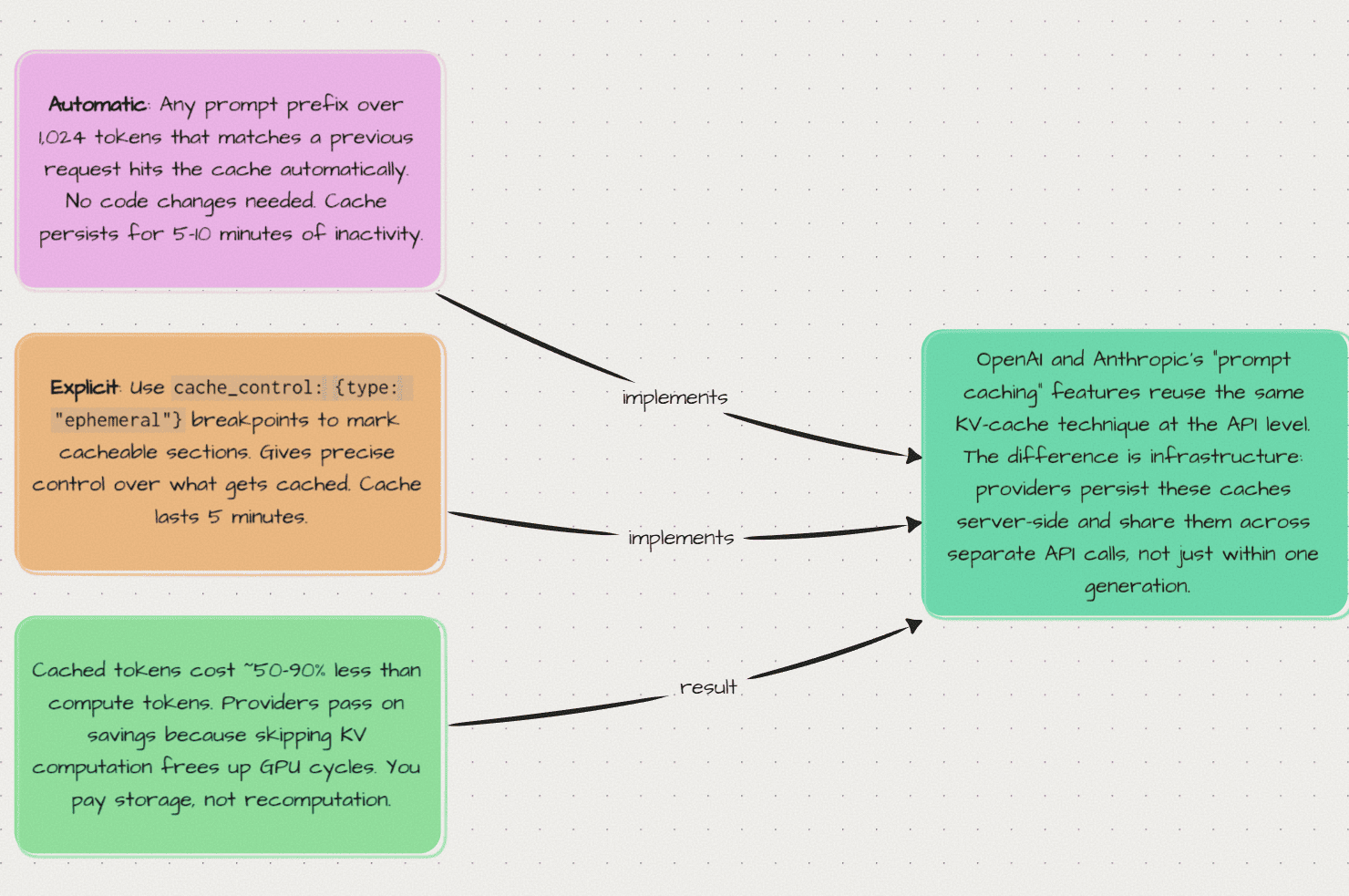
Provider Differences
| Provider | Approach | Minimum Tokens |
|---|---|---|
| OpenAI | Automatic prefix matching | 1,024 |
| Anthropic | Explicit cache_control markers | 1,024 |
This is why reusing prompts with long system instructions or few-shot examples is so cost-effective — you’re not paying for the KV computation twice.
Part 6: Pseudocode Implementation
Here’s simplified Python pseudocode showing how KV-caching works in practice:
class AttentionWithKVCache:
"""Self-attention with KV-cache for efficient generation."""
def forward(self, x, past_kv=None):
"""
Args:
x: Input for NEW tokens only [batch, new_seq, d_model]
past_kv: Cached (K, V) from previous steps, or None
Returns:
output: Attention output
present_kv: Updated cache including current step's K, V
"""
# 1. Project NEW tokens to Q, K, V
q = self.W_q(x) # Query for new token
k_new = self.W_k(x) # Key for new token
v_new = self.W_v(x) # Value for new token
# 2. KV-CACHE LOGIC: Concatenate with past K, V
if past_kv is not None:
past_k, past_v = past_kv
k = torch.cat([past_k, k_new], dim=1) # Append to cache
v = torch.cat([past_v, v_new], dim=1)
else:
# First step: no cache yet
k, v = k_new, v_new
# 3. Compute attention with FULL keys/values (cached + new)
scores = (q @ k.T) / sqrt(d) # Q @ K^T / √d
attn_weights = softmax(scores)
output = attn_weights @ v
# 4. Return updated cache for next step
return output, (k, v)
def generate_with_cache(model, prompt_ids, max_new_tokens=10):
"""Autoregressive generation using KV-cache."""
kv_cache = None # Start with empty cache
generated = prompt_ids.clone()
for _ in range(max_new_tokens):
# Only process the LAST token (or full prompt on first step)
input_ids = generated[:, -1:] if kv_cache is not None else generated
logits, kv_cache = model(input_ids, past_kv=kv_cache)
next_token = logits.argmax(dim=-1)
generated = torch.cat([generated, next_token], dim=1)
return generated
def generate_naive(model, prompt_ids, max_new_tokens=10):
"""Naive generation WITHOUT cache — reprocesses entire sequence each step."""
generated = prompt_ids.clone()
for _ in range(max_new_tokens):
# Re-process ENTIRE sequence every time! O(n²) complexity
logits, _ = model(generated, past_kv=None)
next_token = logits[:, -1:].argmax(dim=-1)
generated = torch.cat([generated, next_token], dim=1)
return generatedKey insight in the code:
generate_with_cache: Each step processes only 1 token → O(n) totalgenerate_naive: Each step reprocesses the entire sequence → O(n²) total
Summary
KV-caching is the technique of storing Key and Value matrices from previously processed tokens, allowing transformers to generate text in O(n) time instead of O(n²).
- Without caching: Recompute K,V for all tokens at every step
- With caching: Only compute K,V for the new token, reuse the rest
- Trade-off: Higher memory usage for dramatically faster generation
If you’d rather see the visuals from this post interactively — zoom in, pan around, look at them side by side — they all live on this dim0 board.
This optimization is essential for making large language models practical for real-time applications, and it’s the same principle behind the cost savings you get from provider prompt caching APIs.